#새로운 분류모델 돌려보기
import warnings
warnings.filterwarnings('ignore')
from sklearn.model_selection import train_test_split
import pandas as pd
# training dataset 불러오기
data = pd.read_csv("C:/Users/lucy8/OneDrive/바탕 화면/train.csv", encoding = 'utf-8')
# 맞춰야 하는 것은 type이기 때문에 type과 나머지 데이터들을 분리해줌
X = data[data.columns[:, :]]
y = data[["class"]]
# training dataset과 test dataset으로 쪼개기
# training과 test의 비율은 0.3
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, random = 42)
scaler = MinMaxScaler()
scaler.fit(X_train)
X_scaled_train = scaler.transform(X_train)
X_scaled_test = scaler.transform(X_test)
#SVM 모델 실행하기
from sklearn import SVC
model = SVC()
model.fit(X_scaled_train, y_train)
pred_train = model.predict(X_scaled_train)
pred_test = model.predict(X_scaled_test)
model.score(X_scaled_train, y_train)#하이퍼 파라미터 분석

-파라미터 C를 이용해 모델이 얼마나 오류를 허용할 것인지
-kernel은 데이터 셋의 형태에 따라 다름 / 선현 linear, 비선형ploy,rdf
-다항식 커널은 degree로 차수를 지정해주고, rdf커널이면 감마와 C값조절 필수
>고민된다면 선형커널부터 시도, 훈련세트가 너무 크지 않으면 rbf도 좋음
#분류모델의 성능평가 방법
-log loss
ex)
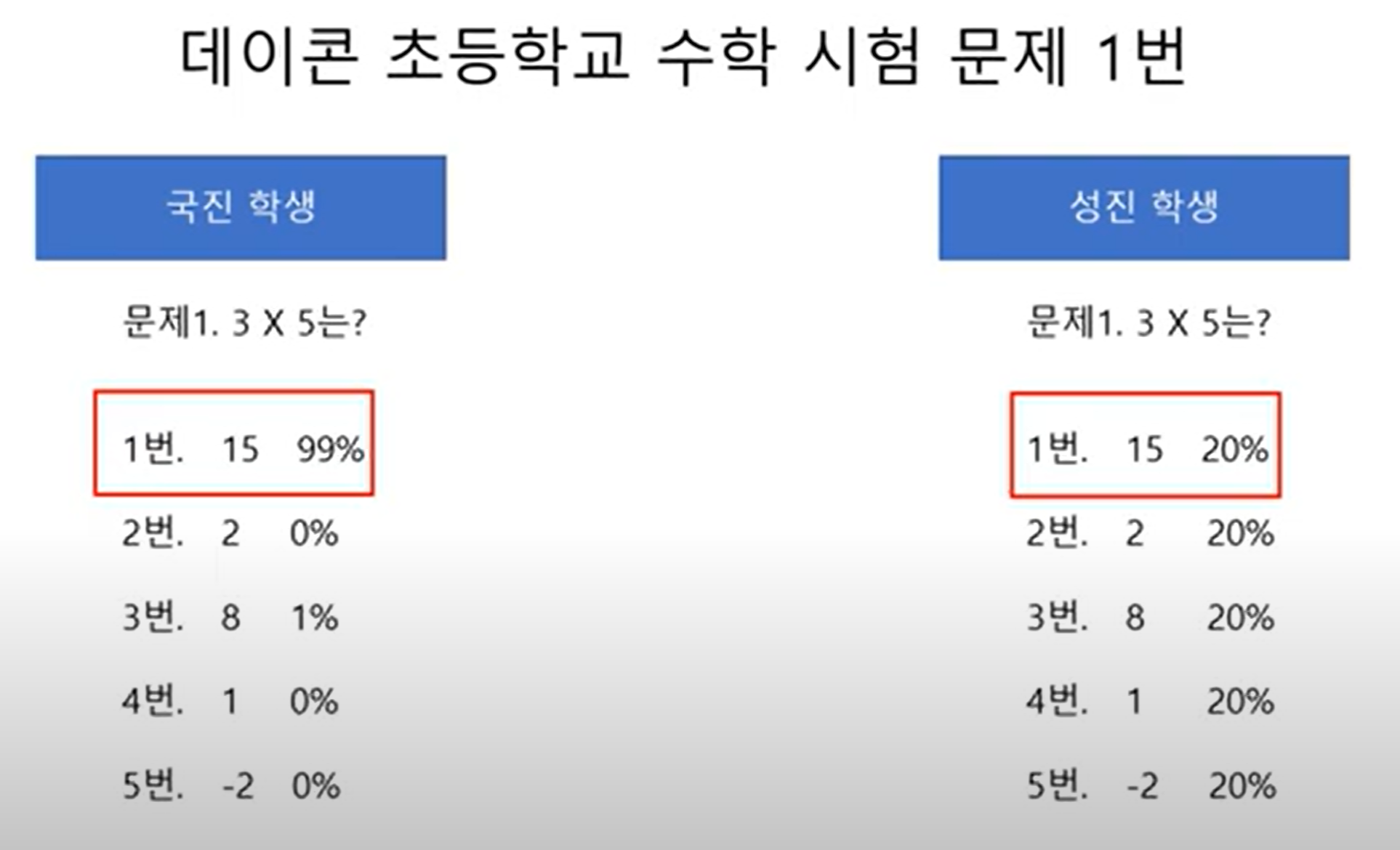
국진학생이 더 열심히 학습함, 결과값만 보면 세부적인 내용을 반영할 수 없음

> 확률값을 직접적으로 평가지표로 활용 (더 정교한 평가를 받을 수 있음)
개념
:모델이 예측한 확률 값을 직접적으로 반영하여 평가
:확률 값을 음의 log함수에 넣어서 변환을 시킨 값으로 평가
>잘못 예측할 수록(실제정답에 대한 에측이 낮아질수록), 패널티를 더 부여하기 위함

확률값이 낮아질수록 기하급수적으로 패널티값이 커짐

-혼동행렬(confusion Matrix)




[출처]
서포트벡터머신(SVM) 개념과 주요 파라미터 정의 (tistory.com)
14. 머신러닝 모델탐구_서포트 벡터 머신 : 네이버 블로그 (naver.com)
[딥러닝] 분류 모델의 성능평가 방법(Precision, Recall, Accuracy, F1Score, Confusion Matrix) (tistory.com)
'💡 WIDA > DACON 분류-회귀' 카테고리의 다른 글
| [DACON/조아영] 파이썬을 이용한 EDA (0) | 2023.04.07 |
|---|---|
| [DACON/김민혜] 파이썬을 이용한 EDA (0) | 2023.04.07 |
| [DACON/김경은] 분류 모델 뜯어보기, 분류 모델 평가방식 (0) | 2023.03.31 |
| [DACON/김규리] 분류 모델 뜯어보기, 분류 모델 평가방식 (0) | 2023.03.31 |
| [DACON/최다예] 분류 모델 뜯어보기, 분류모델 평가방식 (0) | 2023.03.30 |