파이썬에서 많이 사용하는 자료구조에 대해 알아봅시다!
01 자료구조의 이해
> 자료구조의 개념
자료구조(data structure) : 어떤 데이터를 저장할 때 그 데이터의 특징에 따라 컴퓨터에 효율적으로 정리하기 위한 데이터 저장 및 표현 방식
→ 데이터의 특징을 고려하여, 특징이 다른 다양한 형태의 데이터를 저장하여 처리하기 위해 필요하다!

> 파이썬에서의 자료 구조
파이썬에서의 자료 구조의 종류에 대해 알아봅시다.

02 스택과 큐
> 스택

스택(stack) : Last in First Out(LIFO), 가장 마지막에 들어간 데이터가 가장 먼저 나오는 형태로 데이터의 저장 공간을 구현하는 것

일반적으로 사각형의 공간을 뜻함
리스트와 비슷하지만 저장 순서가 바뀌는 형태 ; 스택 자료구조
- 구현방식
Push : 스택에 저장하는 것
Pop : 데이터를 추출하는 것
- pop
>>> a = [1, 2, 3, 4, 5]
>>> a.append(10)
>>> a
[1, 2, 3, 4, 5, 10]
>>> a.append(20)
>>> a
[1, 2, 3, 4, 5, 10, 20]
>>> a.pop()
20
>>> a.pop()
10append로 삽입한 수를 pop으로 추출
pop( )함수를 가용하면 가장 마지막에 저장된 값을 추출하고 동시에 리스트에서 삭제시킴
- 스택 활용하기 - 텍스트 역순 출력
word = input("Input a word: ")
world_list = list(word)
print(world_list)
result = [ ]
for _ in range(len(world_list)):
result.append(world_list.pop())
print(result)
print(word[::-l])입력받은 텍스트는 word에 저장되거, list형으로 변환합니다.
그 후 차례대로 추출하면 텍스트의 역순값이 출력됩니다.
⚡ ‘ _ ‘ 활용
_ 기호는 일반적으로 for문에서 많이 사용되는데 _ 기호가 있으면 해당 반복문에서 생성되는 값은 코드에서 사용하지 않겠다는 뜻이 됩니다.
위의 코드에서는 6행의 range(len(world_list))에서 생성되는 값을 반복문 내에서 사용하지 않기 때문에 _로 할당받은 것입니다.
> 큐
큐(queue) : First in First Out(FIFO) 메모리구조를 갖는 자료구조

ex) 은행 대기 번호표 - 먼저 온 사람이 앞의 번호표를 뽑고, 번호가 빠른 사람이 먼저 서비스를 받는 구조
- 스택과의 차이
스택 : 메모리가 시작하는 점이 고정되어 있음
큐 : 처음에 저장되는 메모리 주소가 값이 사용됨에 따라 계속 바뀜 → 구현이 더 복잡
- 구현 방식
pop(0) : pop( )함수가 리스트의 마지막 값을 가져오는 것이라면, pop(0)은 맨 처음 값을 가져온다는 의미
>>> a = [1, 2, 3, 4, 5]
>>> a.append(10) # a = [1, 2, 3, 4, 5, 10]
>>> a.append(20) # a = [1, 2, 3, 4, 5, 10, 20]
>>> a.pop(0)
1
>>> a.pop(0)
203 튜플과 세트
> 튜플
튜플(tuple) : 리스트와 같은 개념이지만 값 변경이 불가능한 리스트
- 선언과 사용
>>> t = (1, 2, 3)
>>> print(t + t , t * 2)
(1, 2, 3, 1, 2, 3) (1, 2, 3, 1, 2, 3)
>>> len(t)
31행 : 튜플 선언. 괄호를 사용하여 t = (1, 2, 3)과 같은 형태로 선언합니다.
2~3행 : 리스트에서 사용하는 연산, 인덱싱, 슬라이싱이 모두 동일하게 적용됩니다.
- 값 변경 불가
❗튜플의 값을 변경하고자 하면 오류가 발생

맨 아래 오류 메시지 : ’튜플 오브젝트에는 새로운 아이템의 할당을 허용하지 않는다.’
→ 튜플의 가장 큰 특징!
- 값이 하나인 튜플 선언
t = (1) # 변수 t 선언으로 이해
t = (1, ) # 튜플 선언
> 세트
세트(set) : 값을 순서 없이 저장하되 중복을 불허하는 자료형
→ ‘중복을 불허하는’ 기능 덕분에 프로그래밍에서 유용하게 쓰임
- 선언과 사용
>>>s = set([1, 2, 3, 1, 2, 3])
>>>s
{1, 2, 3}세트를 사용하기 위해선 set( ) 함수를 사용하려 리스트, 튜플의 데이터를 넣으면 해당 값이 세트 형태로 변환됩니다.
중복을 제거한 후 세트로 변환되어 출력됩니다.
- 값 삭제 변경 가능
[실습] 세트는 튜플과 다르게 삭제나 변경이 가능합니다.
>>> s
{1, 2, 3}
>>> s.add(1) # 1을 추가하는 명령이지만 중복 불허로 추가되지 않음
>>> s
{1, 2, 3}
>>> s.remove(1) # 1 삭제
>>> s
{2, 3}
>>> s.update([1, 4, 5, 6, 7]) # [1, 4, 5, 6, 7] 추가
>>> s
{1, 2, 3, 4, 5, 6, 7}
>>> s.discard(3)
>>> s
{1, 2, 4, 5, 6, 7}
>>> s.clear()
>>> s
set()add( ) : 원소 하나 추가
remove( ), discard( ) : 원소 하나 제거
update( ) : 새로운 리스트를 그대로 추가
clear( ) : 모든 변수를 삭제
- 집합 연산
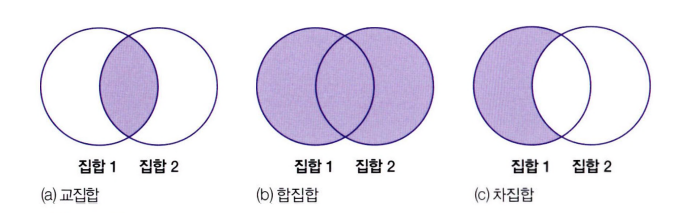
>>> s1 =set([1, 2, 3, 4, 5])
>>> s2 =set([3, 4, 5, 6 ,7])
>>>
>>> s1.union(s2) # s1과 s2의 합집합
{1, 2, 3, 4, 5, 6, 7}
>>> s1 | s2 # set([1, 2, 3, 4, 5, 6, ])
{1, 2, 3, 4, 5, 6, 7}
>>> s1.intersection(s2) # s1과 s2의 교집합
{3, 4, 5}
>>> s1 & s2 # set([3, 4, 5])
{3, 4, 5}
>>> s1.difference(s2) # s1과 s2의 차집합
{1, 2}
>>> s1 - s2 # set([1, 2])
{1, 2}합집합 : union( ), |
두 집합의 중복값을 제거하고 합치는 연산
교집합 : intersection( ), &
두 집합 양쪽에 모두 포함된 값만 추출하는 연산
차집합: difference( ), -
앞에 있는 집합의 원소 중에 뒤의 집합에 포함된 원소를 제거하는 연산

04 딕셔너리
> 딕셔너리의 개념
- 딕셔너리는 영어사전에서 검색을 위해 영어 단어들을 저장해 놓은 방식과 비슷!
- 영어사전에서는 각 단어를 검색할 수 있도록 색인 index을 만들어 놓고 색인을 통해 그 단어를 찾아 의미를 파악한다. → 이와 마찬가지
- 파이썬의 딕셔너리 구조에서는 데이터의 유일한 구분자인 키 key라는 이름으로 검색할 수 있게 한다
- 실제 데이터를 값value 이라는 이름과 쌍으로 저장하여 프로그래머가 데이터를 쉽게 찾을 수 있도록 한다.
>> 파이썬에서의 딕셔너리
딕셔너리 변수 = { 키 1:값 1, 키 2:값 2, 키 3:값 3, ... }: 키 와 값 으로 구성되어있다!
- 특징
- 값에는 다양한 자료형이 들어갈 수 있다.
- 리스트, 튜플, 세트, 딕셔너리까지 사용 가능
- 선언과 사용
>>> student_info = {2023111222:'hanni', 2023111333:'jenni', 2023111444:'lily'}
>>> student_info[2022111333]
>>> 'Jenni'- 키는 문자열로 선언할 수도 있고, 정수형으로도 선언할 수 있다.
- 해당 키를 대괄호 안에 넣어 호출할 수 있다.
- 정수형으로 선언했기 때문에 정수형으로 호출한다.
- 재할당과 데이터 추가
>>> student_info[2023111222]= 'hanni'
>>> student_info[2023111222]
'hanni'
>>> student_info[2023111555]= 'minji'
>>> student_info
{2023111222: 'hanni', 2023111333:'jenni', 2023111444:'lily', 2022111555:'lily'}}- 키를 사용하여 값을 할당하면 된다.
> 딕셔너리의 함수
- keys( )
>>> country_code.keys() # 딕시너리의 키만 출력
dict_keys(['America', 'Korea', 'China', 'Japan'])- values( )
>>> country_code["German"] = 49 # 딕셔너리 추가
>>> country_code
{'America': 1, 'Korea': 82, 'China': 86, 'Japan': 81, 'German': 49}
>>> country_code.values() # 딕셔너리의 값만 출력
dict_values([l, 82, 86, 81, 49])- items( )
>>> country_code.items() # 딕셔너리 데이터 출력
dict_items([('America'), ('Korea', 82), ('China', 86), ('Japan', 81), ('German', 49)])- 딕셔너리와 for문
>>> for k, v in country_code.items():
... print("Key:", k)
... print("Value:", v)- 딕셔너리와 if문
>>> "Korea" in country_code.keys()
True
>>> 82 in country_code.values()
True05 collections 모듈
> 모듈의 개념
collections 모듈 : 파이썬의 내장 자료구조
→ 리스트, 튜플, 딕셔너리 등을 확장하여 제작된 파이썬의 내장 모듈
→ 기존의 자료구조보다 효율적이고 편리
자료구조 호출 코드
from collections import deque
from collections import OrderedDict
from collections import defaultdict
from collections import Counter
from collections import namedtuple> 모듈의 종류
>>deque 모듈
→ 스택과 큐를 모두 지원하는 모듈
- 선언과 사용
>>> from collections import deque
>>>
>>> deque_list = deque()
>>> for i in range(5):
... deque_list.append(i)
>>> print(deque_list)
deque([0, 1, 2, 3, 4])1행 - import
3행 - 리스트와 비슷한 형식으로 데이터를 저장
4행 - append( ) 함수를 사용해 기존 리스트처럼 데이터가 인덱스 번호를 늘리면서 쌓임
[스택]
>>> deque_list.pop()
4
>>> deque_list.pop()
3
>>> deque_list.pop()
2
>>> deque_list
deque([0, 1])deque_list.pop 수행 시 오른쪽 요소부터 하나씩 추출됨
→ 스택과 같이 마지막에 넣은 값이 먼저 추출됨
[큐]
>>> from collections import deque
>>>
>>> deque_list = deque()
>>> for i in range(5):
... deque_list.appendleft(i)
>>> print(deque_list)
deque([4, 3, 2, 1, 0])→ pop(0) 대신 appendleft( ) 함수로 새로운 값을 왼쪽부터 입력하도록 하여 먼저 들어간 값부터 출력될 수 있도록 함.
-장점 : 기존의 리스트와의 비교할 때 몇 가지 장점이 있다.
1) 연결 리스트의 특성 지원
연결 리스트 : 데이터를 저장할 때 요소의 값을 한 쪽으로 연결한 후, 요소의 다음 값의 주소값을 저장하여 데이터를 연결하는 기법

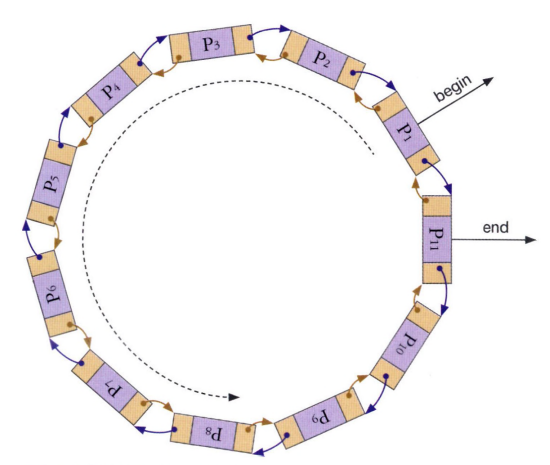
연결 리스트는 그림처럼 다음 요소의 주소값을 저장하므로 데이터를 원형으로 저장할 수 있다. 또한, 마지막 요소에 첫 번째 값의 주소를 저장시켜 해당 값을 찾아갈 수 있도록 연결시킨다.
이러한 특징 때문에 가능한 기능 : rotate( ) 함수
rotate( ) : 기본 deque에 저장된 요소들 값의 인덱스를 바꾸는 기법
- 원형의 데이터 구조를 갖기 때문에 각 요소의 인덱스 번호를 하나씩 옮긴다면 실제로 요소를 옮기지 않아도 인덱스 번호를 바꿀 수 있다.
- 예시코드
>>> from collections import deque
>>>
>>> deque_list = deque()
>>> for i in range(5):
deque_list.appendleft(i)
>>> print(deque_list)
deque([0, 1, 2, 3, 4])
>>> deque_list.rotate(2)
>>> print(deqiie_list)
deque([3, 4, 0, 1, 2])
>>> deque_list.rotate(2)
>>> print(deque_list)
deque([1, 2, 3, 4, 0])rotate(2) 함수를 수행시키면 값이 두 칸씩 이동하는 것을 알 수 있습니다.
2) 다양한 기능 제공
- reversed( ) 함수 - 기존과 반대로 데이터를 저장
- 예시코드
...
>>>print(deque(reversed(deque_list)))
deque([0, 4, 3, 2, 1])
3) 기존의 리스트에서 지원하는 함수 사용 가능
- extend( ), extendleft( ) : 리스트가 통째로 오른쪽으나 왼쪽으로 추가됨
- 예시코드
>>> deque_list.extend([5, 6, 7])
>>> print(deque_list)
deque([1, 2, 3, 4, 0, 5, 6, 7])
>>> deque_list.extendleft([5, 6, 7])
>>> print(deque_list)
deque([7, 6, 5, 1, 2, 3, 4, 0, 5, 6, 7])4 )메모리의 효율적 사용과 빠른 속도
>>OrderedDict 모듈
ordered dictionary : 순서를 가진 딕셔너리
→ 기존의 딕셔너리 파일을 저장하면 키는 저장 순서와 상관 없이 저장된다.
→ 하지만 OrderedDict 모듈은 키의 순서를 보장!
[다양한 방법들]
- 저장한 순서대로 화면에 출력
from collections import OrderedDict # OrderedDict 모듈 선언
d = OrderedDict()
d['x'] = 100
d['y'] = 200
d['z'] = 300
d['l'] = 500
for k, v in d.items():
print(k, v)어떤 컴퓨터든 상관 없이 x, y, z, l의 순서대로 키-값 쌍이 출력된다.
- 키와 값 정렬 ex)키를 이용하여 주민등록번호를 번호순으로 정렬 후 출력
def sort_by_key(t):
return t[0]
from collections import OrderedDict # OrderedDict 모듈 선언
d = dict()
d['x'] = 100
d['y'] = 200
d['z'] = 300
d['l'] = 500
for k, v in OrderedDict(sorted(d.items(), key=sort_by_key)).items():
print(k, v)l 500
x 100
y 200
z 300딕셔너리의 값인 변수 d를 리스트 형태로 만든 다음, sorted( ) 함수를 사용하여 정렬
그리고 다시 OrderedDict 모듈로 감싸주는 방식
→ 이렇게 하면 기존의 딕셔너리나 리스트의 순서를 지키면서 딕셔너리 형태로 관리할수 있다.
>>defaultdict Counter 모듈
defaultdict 모듈 : 딕셔너리의 변수를 생성할 때 키에 기본값을 지정하는 방법
→ 새로운 키를 생성할 때 별다른 조치 없이 새로운 값을 생성할 수 있음
- 선언과 사용
d = dict()
print(d["first"])from collections import defaultdict
d = defaultdict(lambda: 0) # Default 값을 설정
print(d["first"])3행 d = defaultdict(lambda: 0) : defaultdict 모듈을 선언하면서 동시에 초깃값을 0으로 설정한 것
lambda(0) 함수 : 어떤 키가 들어오더라도 처음 값은 전부 0으로 설정한다.
- 장점 : 코드의 수를 줄일 수 있다.
>>Counter 모듈
Counter 모듈 : 시퀀스 자료형의 데이터 값의 개수를 딕셔너리 형태로 반환하는 방법
→ 리스트나 문자열과 같은 시퀀스 자료형에 저장된 요소 중에서 같은 값이 몇 개 있는지 그 개수를 반환
- 선언과 사용
>>> from collections import Counter
>>>
>>> text = list("gallahad")
>>> text
['g' 'a', 'l', 'l', 'a', 'h', 'a', 'd']
>>> c = Counter(text)
>>> c
Counter({'a': 3, 'I': 2, 'g': 1, 'h': 1, 'd': 1})
>>> c["a"]
3
>>namedtuple 모듈
namedtuple 모듈 : 튜플의 형태로 데이터 구조체를 저장하는 방법
→ 여러 정보를 하나의 튜플 형태로 구성해 손쉽게 사용할 수 있는 자료구조
- 선언과 사용
>>> from collections import namedtuple
>>>
>>> Point = namedtuple(Point1, ['x', 'y'])
>>> p = Point(ll, y=22)
>>> p
Point(x=ll, y=22)
>>> p.x, p.y
(11, 22)
>>> print(p[0] + p[l])
33'📚 스터디 > 파이썬 스터디 강의자료' 카테고리의 다른 글
| [2팀/김가림, 최다예] 7차시 파이썬 스터디 자료구조 (1) | 2023.05.11 |
|---|---|
| [2팀/김세연] 7차시 파이썬 스터디 - 자료구조 (1) | 2023.05.11 |
| [3팀/김규리] 7차시 파이썬 스터디 - 자료구조 (2) | 2023.05.10 |
| [3팀/김경은] 7주차 파이썬 스터디 - 자료구조 (1) | 2023.05.10 |
| [4팀/김민혜] 7차시 파이썬 스터디 - 자료구조 (0) | 2023.05.09 |