2차시_자료형_과제.docx
2.41MB
2차시_자료형_강의안.pdf
1.79MB
*모든 출처는 도서 "데이터 과학을 위한 파이썬 프로그래밍"입니다
# 1. 변수의 이해
변수와 값
- 변수?
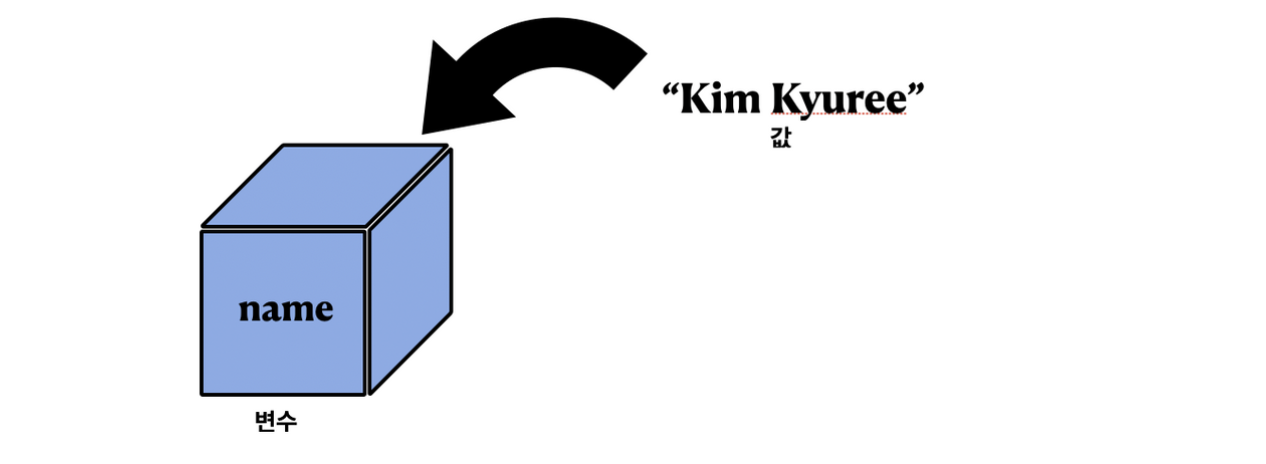
- “name = ‘Kim Kyuree’”
- name이라는 공간에 Kim Kyuree라는 글자를 넣어라!
- name이라는 변수에 Kim Kyuree라는 값을 넣어라
- “name = ‘Kim Kyuree’”
name = 'Kim Kyuree'
print(name) #Kim Kyuree
name = 'Kim Kyuree'
print(name) #Kim Kyuree- 변수에 값 할당하기
- ‘=’ 기호 활용
- 값을 변수에 넣어라
- 기본 문법
- [변수명 = 값]
- ‘=’ 기호 활용
-
- 변수 a에 3, 변수 b에 5를 할당하는 것은 동일
- 따옴표(’ ‘) 사용 여부의 차이
- 예제 ) print(a+b) vs. print( ’a + b’)
a = 3
b = 5
print(a + b) #8
a = 3
b = 5
print('a + b') #a + b- 변수 a에 3, 변수 b에 5를 할당하는 것은 동일
- 따옴표(’ ‘) 사용 여부의 차이

→ 따옴표 안의 값을 하나의 값으로 간주
💭 파이썬에서는 변수와 값을 통해 모든 프로그래밍 시작!
변수명 선언
- 규칙
- 알파벳, 숫자, 밑줄(_)로 구성가능 (* 숫자로 시작할 수 없다)
- Ex. name, age, num1, total_score ,
1num, 5_stars
- Ex. name, age, num1, total_score ,
- 변수명은 의미 있는 단어로 선정
- Ex. student_name, score, id ..
- 변수명 대소문자 구분
- Ex, option과 Option은 **다른 **변수
- 특별한 의미가 있는 예약어는 사용불가
- Ex. for, if, else, print, input, as, type..
- 함수명, 명령 키워드
- 알파벳, 숫자, 밑줄(_)로 구성가능 (* 숫자로 시작할 수 없다)
- 유의할 점
- 의미있는 이름으로 선언 for 타인과 의사소통
- ex. a , b ,c … → 변수의 값 의미 알아채기 어렵..
- 변수 관련 에러
- NameError: name ‘xx’ is not defined
- 변수명에 오타 있거나, 선언하지 않았거나 등..
- 의미있는 이름으로 선언 for 타인과 의사소통
#2. 자료형과 기본 연산
기본 자료형
- 정수형(inter type): 자연수 포함, 값의 영역이 정수로 한정된 값
- -1, 0, 1, 49 ..
- ex. data = 1
- 실수형(floating type): 소수점이 포함된 값
- 10.2, 6.0, -0.3 ..
- 9 vs 9.0
- 문자형(string type): 문자로 출력되는 값, ‘ ‘ & “ “ 안에 포함되는 값
- ‘apple’, ‘abc’ ..
- print(”a+b”) vs. print(a+b)
- 불린형(boolean type): 논리형, 참 혹은 거짓, True False
- True, False

간단한 연산
- 연산자& 피연산자
- 연산자 : + - * %
- 피연산자 : 연산자에 의해 계산되는 숫자
- ex. 3+2 → 3,2 피연산자, + 연산자
- 수학에서의 연산자 역할, 연산순서 동일
- 사칙연산
- +, - ⇒ 덧셈, 뺄셈
- , / ⇒ 곱셈, 나눗셈
- 25 + 37 # 62 50 - 19 # 31 50 * 3 # 150 30 / 5 # 6.0
- +, - ⇒ 덧셈, 뺄셈
- 제곱승
- 연산자: **
- 3의 5승 ⇒ 3**5
- 3 * 3 * 3 * 3 * 3
- 연산자: **
- 나눗셈의 몫과 나머지
- 몫 반환 연산자: //
- ex. 7//4 → 1
- 나머지 반환 연산자: %
- ex. 7%4 → 3
- 괄호 사용 : (), 괄호 안 우선 계산
- ex. 2*(3+4) → 14
- 몫 반환 연산자: //
- 증가 연산 & 감소 연산
- 증가 연산 : [변수 += 더할 값]
- ex. a = a + 1 < = > a += 1
- 감소 연산: [변수 -= 뺄 값]
- 증가 연산 : [변수 += 더할 값]
- a = 1 a = a + 1 print(a) #2 a += 1 #a에 1 더하기 print(a) #3 a = a - 1 #2 a -= 1 #a에서 1 빼기 print(a) #1
- +) 연산자 이용 연결
- 숫자 + 숫자 → 더하기
- 문자 + 문자 → 두 문자 이어 연결
- 문자 * 숫자 → 문자를 숫자만큼 반복
- 이 경우, * 제외 모두 오류 발생
#3. 자료형 변환
정수형과 실수형 간의 변환
- 프로그래밍, 4가지 자료형 자유롭게 변환하여 다루는 경우 많음
- 인터넷 로그인
- float()함수 ; 정수 → 실수⇒ 자료형 변환 시, 전혀 다른 수가 됨 !⇒ 정수형 나눗셈 결과도 실수형( * 파이썬 인터프리터의 특징, 스스로 실수형으로 변환)
- #실수형 a = 10 b = 3 print(a / b) #3.33333..
- #정수형 a = 10 print(a) #10 #실수형 a = float(10) print(a) #10.0
- int()함수 ; 실수 → 정수⇒ 정수형 변환으로 소수점 이하 내림 발생( * 기존의 수학과 차이점)
- #실수형을 정수형으로 변환 a = int(10.7) b = int(10.3) #출력값 확인 print(a + b) #20 print(a) #10 print(b) #10
숫자형과 문자형 간의 변환
- 쌍방향 변환 가능
- 문자형 → 정수 & 실수형 변환 가능, 역도 가능!
: a 문자형으로 선언 → float()함수 통해 b 실수형 값 할당 → 동일한 값 출력a = '76.3' b = float(a) #문자형 print(a) #76.3 #실수형 print(b) #76.3 print(a+b) #error 발생 - but a+b ? ⇒ 숫자형과 문자형은 기본 연산 불가 , 자료형 통일 필요
- Traceback (most recent call last):TypeError: can only concatenate str (nor "float") to str
- File "<stdin>", line 1, in <module>
- str()함수 ; 문자형 아닌 자료형 → 문자형⇒ 문자형 간 덧셈 : 문자열 간 단순 연결(단순 붙이기)
- #실수형 a = float(a) b = a print(a+b) #152.6 #문자형 a = str(a) b = str(b) print(a+b) #76.376.3
자료형 확인하기
- 변수의 자료형 헷갈릴 때!
- type() 함수→ 별도의 출력함수 사용하지 않을 때
- a = int(10.3) b= float(10.3) c = str(10.3) #자료형 출력 type(a) #<class 'int'> type(b) #<class 'float'> type(c) #<class 'str'>
#4. 리스트의 이해
리스트가 필요한 이유
- 배열 (array)
- 가장 많이 사용하는 자료형
- ex. 학생 100 명의 성적 채점할 때 →
변수 100 개 활용/ 한 개 변수에 모든 학생 성적 담기 !
- ex. 학생 100 명의 성적 채점할 때 →
- 가장 많이 사용하는 자료형
- 한 변수에 모든 값 저장 방식 , 배열 in programming / 리스트 in python
개념
- 한 변수에 여러 값 저장하는 자료형
- 시퀀스 자료형(sequence type)
- 여러 데이터 한 변수에 저장하는 기법
- 여러 자료 순서대로 저장
- 정수, 실수, 변수 등 다양한 자료형 저장 가능
- #문자형,정수형,실수형 a = [’color’,1,0.2] #중첩 리스트 color = ['red','blue'] a[0] = color print(a) #[['red','blue'],1,0.2]
- 리스트 생성
- 리스트 명 = [값, 값, 값, .. ]
- 빈 리스트 생성
→ 실제 담긴 값: 문자형의 red, blue, green#리스트에 값 할당 colors = ['red','blue','green'] #리스트에 값 할당 - 개별 데이터 colors = 'red' colors = 'blue' colors = 'green' #빈 리스트 abc =[] - → 대괄호([]) 사용, 콤마(,)로 요소 구분
인덱싱 & 슬라이싱
리스트 다루기 위해 반드시 이해할 것
- 인덱싱(indexing)
- 저장된 값에 접근하기 위해 상대적인 주소 사용
- 주소 ⇒ 첫 번째 값이 0일 경우, 이와 얼마나 떨어져 있는지
- 주소 or 인덳스 값
colors = ['red','blue','green'] print(colors[0]) #red print(colors[1]) #blue print(colors[2]) #green #colors의 길이 print(len(colors)) #3- colors 인덱스
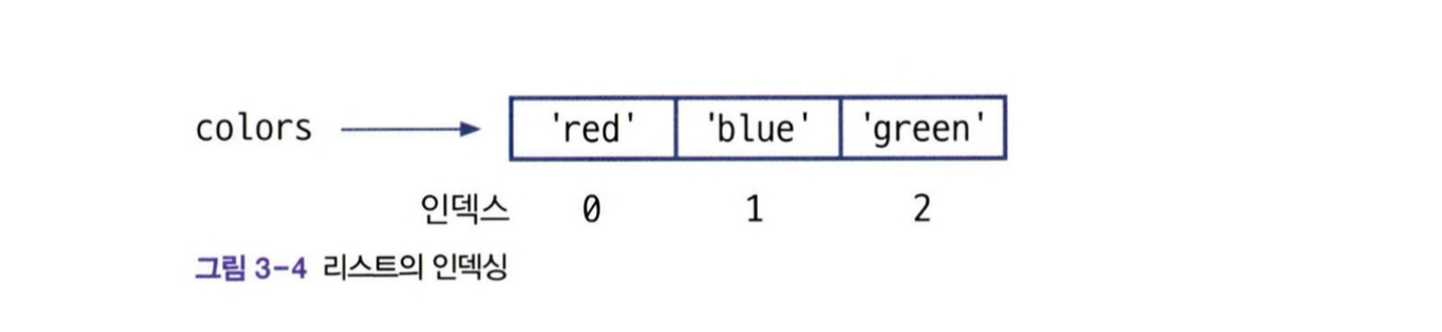
→ 0번째부터 0, 1, 2 주소값으로 호출 가능
→ len() 함수 : length, 리스트 길이 반환, 값의 개수 반환
+ 왜 인덱스는 0부터 시작할까?
: 대부분 프로그래밍 언어 주소값 0부터 시작, 이진수
- 슬라이싱(slicing)
- 인덱스 사용 → 리스트 값 중 일부 추출
cities = ['서울’,’부산’,’인천’,’대구’,’대전’,’광주’,’울산’,’수원’]

- 슬라이싱 기본 문법
- 리스트명[시작 인덱스 : 마지막 인덱스]
→ 우리의 예상 - 서울 ~ 대구 / 실제 출력값 - 서울 ~ 인천</aside>→ 실제 출력: [시작 인덱스 : 마지막 인덱스 - 1]cities[0:3] #['서울','부산','인천']- 예제
#서울부터 대전 cities[0:5] #['서울','부산','인천','대구','대전'] #인천부터 광주 cities[2:6] #광주부터 수원 cities[5:] #['광주','울산','수원'] - → 입력: [시작 인덱스 : 마지막 인덱스]
- 💭 마지막 인덱스 - 1까지 출력 in python
- 리버스 인덱스
- 마지막 값부터 인덱스 시작
- 가장 마지막 값부터 -1 부여 → 첫째 값까지 역순 부여

#리스트 전체 값
cities[-8:] #['서울', ~,'수원']
→ -8부터 인덱스 끝까지 출력
- 활용
- 처음부터 → [: n] (*출력되는 마지막 값 :(n-1)번째)
- 끝까지 → [n :]
- 인덱스 범위 초과 슬라이싱
- 인덱스 시작 값, 마지막 값 비어 있어도 작동
→ 인덱스 범위 초과 or 입력하지 않으면 자동으로 지정됨#cities 모든 값 반환 cities[0:9] cities[0:] cities[:] #인덳스 값 초과 cities[-50:50] #cities 전체 값 출력됨 - 증가값(step)
- 리스트명[시작 인덱스: 마지막 인덱스: 증가값]
#전체 값 출력 - 2칸 단위 cities[::2] #[‘서울’,’인천’,’대전’,’울산’] #전체 값 출력 - 1칸 단위 & 역순 cities[::-1] #['수원','울산',~'서울']
연산
- 덧셈→ 덧셈 연산 : 각 리스트 하나의 리스트로 합쳐져 출력
- → 기존 color1, color2 영향 받지 않음 (*len()으로 확인)
- color1 = ['red','blue','green'] color2 = ['orange','black','pink'] #두 리스트 합치기 - 1 print(color1 + color2) #['red','blue','green','orange','black','pink'] #두 리스트 합치기 - 2 total_color = color1 + color2 print(total_color) #위와 동일 #기존 리스트 변화 확인 len(color1) #3
- 곱셈
- 리스트 x n → 리스트 n회 반복
#2회 반복 color1 * 2 #['red','blue','green','red','blue','green'] - in 연산
- 특정 값 포함여부 확인 연산
color2 = ['orange','black','pink'] #문자열 'blue' 포함여부 확인 'blue' in color2 #False
추가 & 삭제 & 값 변경
- 한 눈에 보기

- 추가 - append() 함수
- 리스트 맨 마지막 새로운 값 추가
color = ['red','blue','green'] #'white' 추가 color.append('white') #확인 color #['red','blue','green','white']- 직접 입력받아 추가
#살 물건 입력받기 to_get = [] item = input("살 물건을 입력해주세요 ->") to_get.append(item) print(to_get)

- 추가 - extend() 함수
- 덧셈 연산
- 값 추가 X → 기존 리스트에 새로운 리스트 추가
color = ['red','blue','green'] color.extend(['black','purple']) color #['red','blue','green','black','purple'] - 추가 - insert() 함수
- append와 차이점
- 특정 위치(지정 위치)에 값 추가
→ 기존 값 인덱스 하나씩 밀림color = ['red','blue','green'] color.insert(0, 'orange') color #['orange','red','blue','green'] - append와 차이점
- 제거 - remove() 함수
- 특정 값 삭제
- 기본문법
- remove(’값’)
→ 다음 값들 한 칸씩 앞으로 이동color = ['red','blue','green'] color.remove('red') color #['blue','green'] - 제거 - del 함수
- 기본 문법
- del 리스트명[인덱스]
color = ['red','blue','green'] del color[0] color #['blue','green']- 일반적으로 변수 자체 삭제 명령
- but 리스트 내 인덱스 지정 → remove()함수와 동일한 기능
- 기본 문법
- 값 변경
- 리스트명[인덱스 값] = 데이터
→ 특정 인덱스의 값 변경할 때 인덱스에 새로운 값 할당color = ['red','blue','green'] color[0] = 'orange' color #['orange','blue','green']- 심화
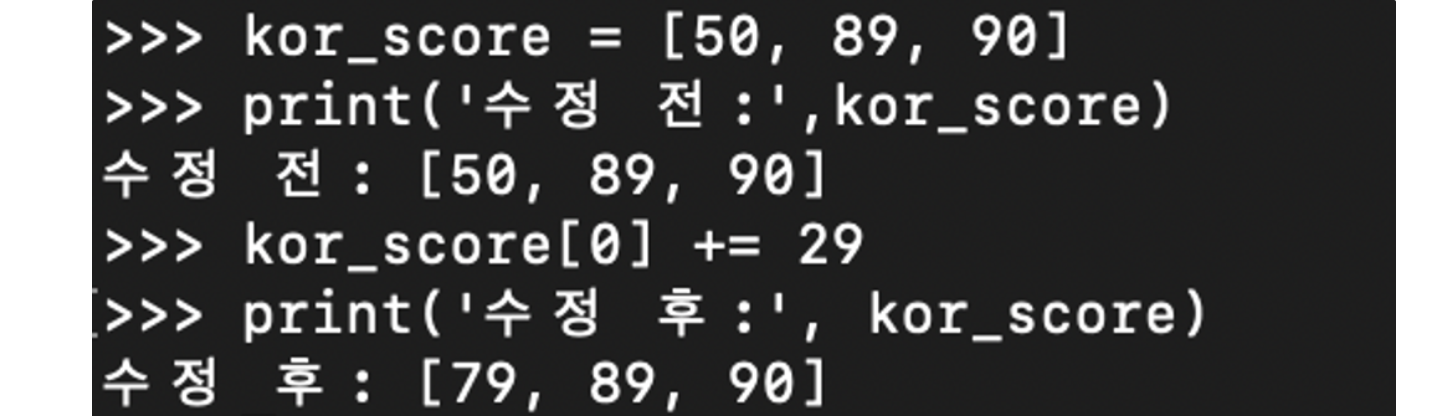
- 증가 연산
#국어 점수 3개월 간 변화 추이 kor_score = [50, 89, 90] print('수정 전:',kor_score) kor_score[0] += 29 print('수정 후:', kor_score)
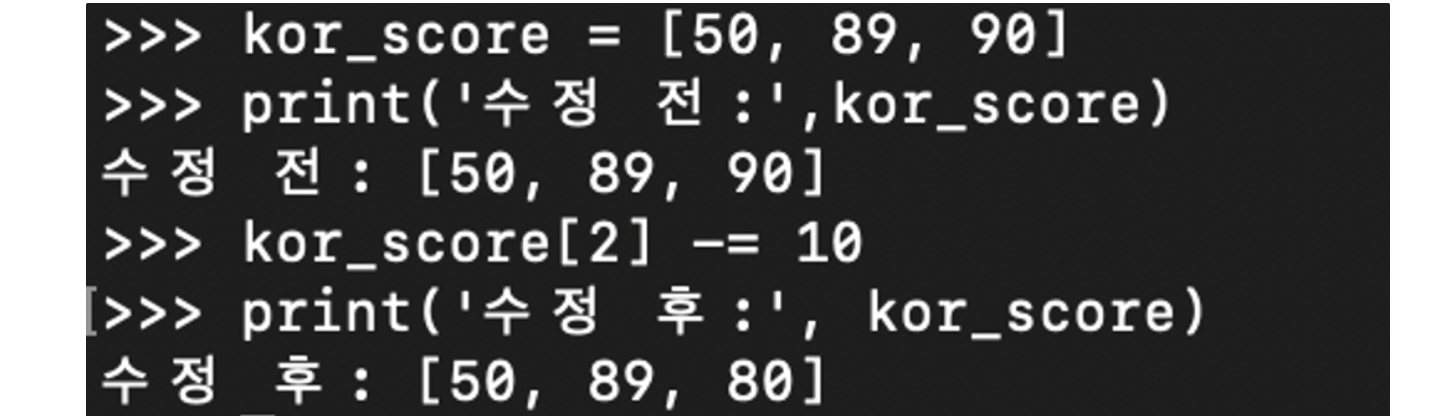
- 감소연산
#국어 점수 3개월 간 변화
kor_score = [50, 89, 90]
print('수정 전:',kor_score)
kor_score[2] -= 10
print('수정 후:', kor_score)
다양한 명령어
- 정렬
- 기본 문법
- 리스트명.sort()
- 오름차순 정렬 - 한글 : 가나다순, 영어 : 알파벳순
fruit = ['사과','바나나','딸기','귤','청포도'] fruit.sort() print('정렬 후:',fruit) - 기본 문법

- 내림차순 정렬 - reverse=True
fruit = ['사과','바나나','딸기','귤','청포도']
fruit.sort(reverse=True)
print('정렬 후:',fruit)

- 최댓값 , 최솟값, 합
- max() ; 최댓값 / min() ; 최솟값
#국어 점수 3개월 간 변화 추이 kor_score = [50, 89, 90] #최댓값 print(max(kor_score)) #90 #최솟값 print(min(kor_score)) #50- sum() ; 합
print(sum(kor_score)) #229 - 인덱스 찾기
- 기본 문법
- 리스트명.index(찾으려는 데이터)
- 해당 값의 인덱스 값 반환
- 기본 문법
패킹 & 언패킹
- 리스트 사용법
- 시퀀스 자료형에서 사용됨
t = [1,2,3] #패킹
a, b, c = t #언패킹
print(t,a,b,c) #[1,2,3]123
- 패킹 : 한 변수에 여러 데이터 할당(= 리스트)
- 언패킹 : 한 변수 여러 데이터 있을 때, 각 변수로 반환
- 리스트 값 개수 = 할당할 변수 개수 (서로 다르면 에러 발생!)
2차원 리스트
- for 리스트 효율적 활용, 여러 개 리스트 → 한 변수에 할당
- 행렬과 같은 개념
- 예제) 학생별 국어, 수학, 영어 점수 표

- 코드
- #2차원 리스트 생성 kor_score = [49, 80, 20, 100, 80] math_score = [43, 60, 85, 30, 90] eng_score = [49, 82, 48, 50, 100] midterm_score = [kor_score, math_score, eng_score]
- 실행화면

- 2차원 리스트 접근
- 대괄호 2 개 사용하여 인덱싱
→ 첫째 [n] : n 행 / 둘째 [m] : m 열#1행 3열 값 출력 print(midterm_score[0][2]) #20- 입력 : n행, m열
- 실제 출력: n+1 행, m+1 열
- 인덱스의 상대적 주소 활용하는 특징때문!
- 앞서 1차원 리스트 인덱싱 주소값과 동일한 특징
'📚 스터디 > 파이썬 스터디 강의자료' 카테고리의 다른 글
| [3팀/이지현] 2차시 파이썬 스터디 - 자료형 (0) | 2023.03.15 |
|---|---|
| [2팀/김가림, 최다예] 2차시 파이썬 스터디 - 자료형 (2) | 2023.03.15 |
| [1팀/허서원] 1차시 파이썬 스터디 - 입출력 (0) | 2023.03.09 |
| [4팀/이나경] 1차시 파이썬 스터디 - 입출력 (0) | 2023.03.09 |
| [2팀/김세연] 1차시 파이썬 스터디 - 입출력 (0) | 2023.03.09 |