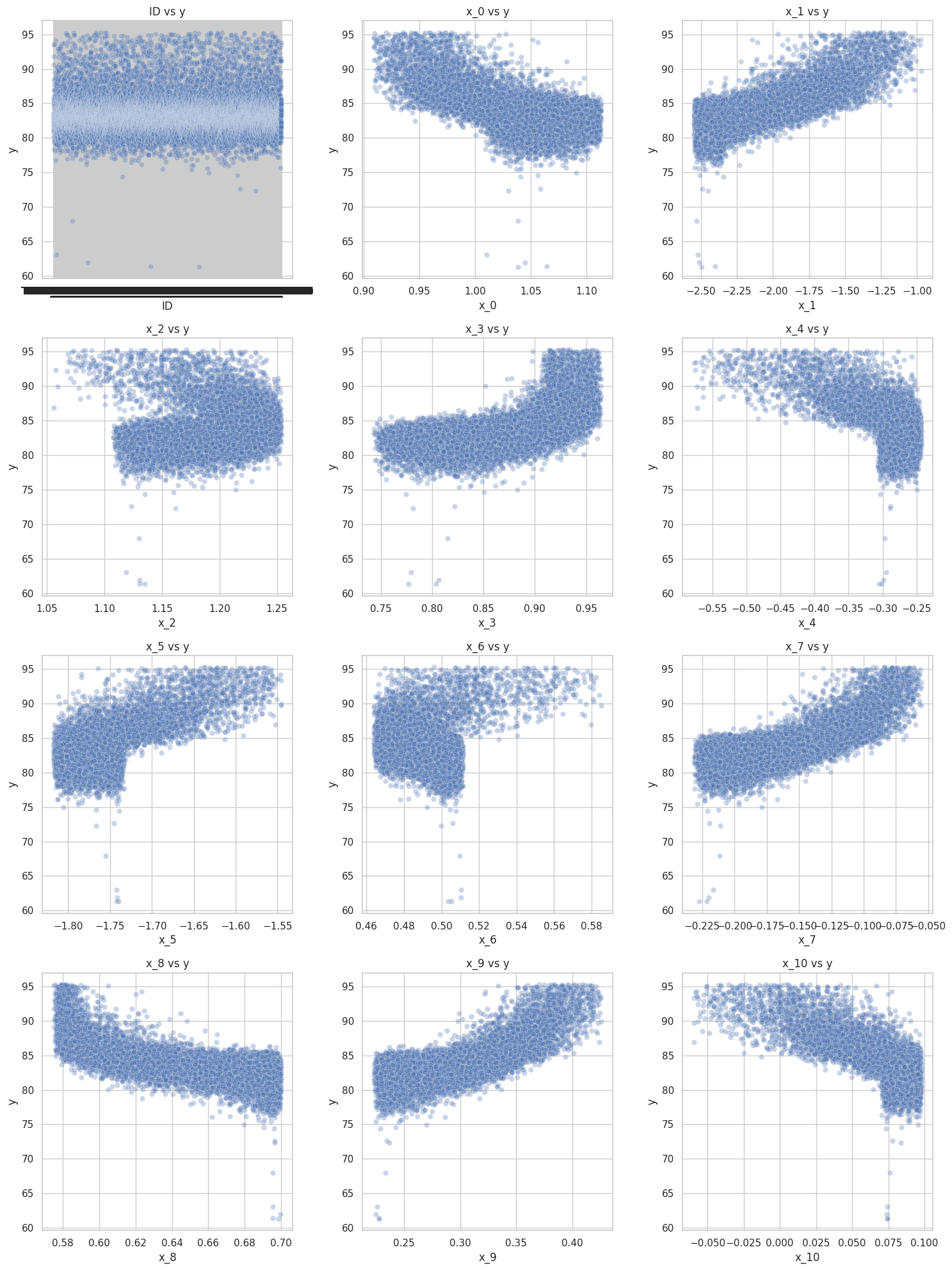
[주제]Model기반 Black-box 최적화 알고리즘 개발 [도메인]반도체 공정이 점점 미세화됨에 따라 최적의 공정 파라미터를 찾는 것은 매우 어려운 문제가 되고 있으며, 이를 해결하기 위해 과거 데이터를 기반으로 학습한 모델을 활용하는 오프라인 모델 기반 최적화가 활용된다.그러나 데이터 분포를 벗어난 파라미터에 대해서는 모델의 예측 신뢰도가 낮아질 수 있어, 데이터 분포와 최적화 결과 간의 균형을 고려함으로써 공정 성능 향상 및 시간·비용 절감을 달성할 수 있다. [프로젝트 계획]- 다양한 탐색 전략 및 모델 비교 분석으로 최적의 하이퍼 파라미터 도출 및 높은 최적화 성능 달성- 데이터의 특징 및 변수 간 상관관계를 분석해 피처 엔지니어링 수행- Black-box 환경에서의 탐색 성능 향상을 위한 모..