과정
1. EDA 및 전처리
2. 모델링 및 결과
3. 인사이트 도출
1. EDA 및 전처리

Training set의 경우 총 23개의 column으로 이루어져 있으며 데이터는 약 20만건이 존재한다.

Test set의 경우 총 22개의 column으로 Training set과는 다르게 'type' column이 존재하지 않는다.
이는 Test set을 이용해 예측 후 submission 파일을 만들어 제출하는 용도이기 때문이다.

Submission file의 경우 column은 test set의 데이터 id, 별들의 type들이 존재한다.
각 type을 어느정도의 확률로 예측했는지 기록 후 제출하는 형태이다.
평가 방법은 log_loss를 이용하라고 했으나, 일단은 정확도와 전반적인 예측 확률 위주로 확인하고자 한다.
1) 수치, 텍스트 해석
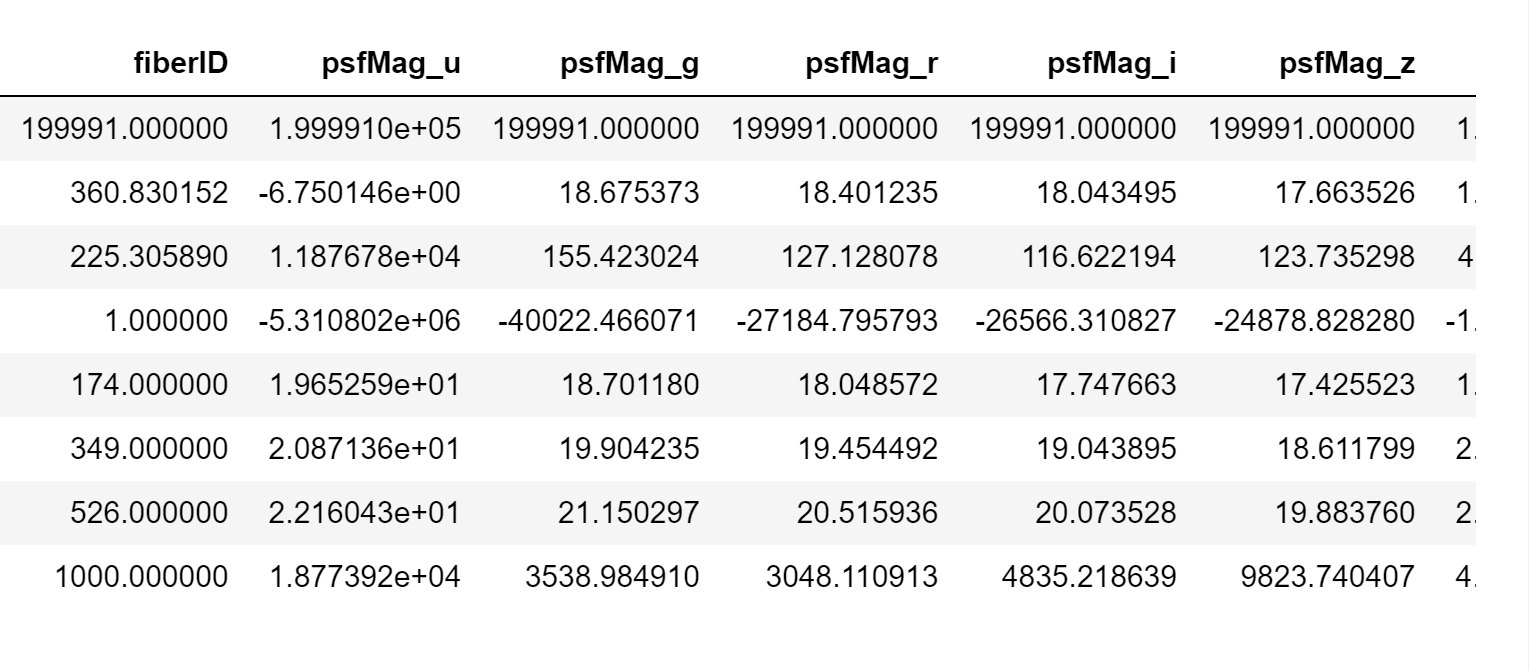
전반적인 기초통계량을 확인해본 결과 최댓값과 최솟값 사이의 갭이 굉장히 크다.
정규화의 과정을 거치거나 outlier를 제거해야할 듯 하다.

column들은 이렇게 구성되어있으며 각 column별 설명은 다음과 같다.
1. id
인덱스와 유사한 존재이다.
2. type
우리가 예측하고자 하는 별의 종류이다.
굉장히 다양한 종류가 있으며, 이에 대해서는 추후에 추가하도록 한다.
3. fiberID
별을 측정할 때 사용한 광섬유의 ID이다.
4. psfMag_u, g, r, i, z
뒤에 붙어있는 u, g, r, i, z는 각각 파장을 의미한다.
psfMag는 점확산함수를 이용해 측정한 별의 광도를 의미하는 듯 하다.
5. fiberMag_u, g, r, i, z
마찬가지로 '_' 뒤에 붙어있는 알파벳은 각각 파장을 의미한다.
fiberMag의 경우 광도를 측정한 광섬유 기준의 광도를 의미하는 듯 하다.
6. petroMag_u, g, r, i, z
petrosian이라는 측정 시스템이 있는데, 이를 이용해 측정한 광도를 의미하는 듯 하다.
7. modelMag_u, g, r, i, z
모델함수를 이용해 측정된 광도를 의미한다.
여기서 모델 함수라는 것이 구체적으로 무엇인지는 알아내지 못했다.

각 column들은 type을 제외하고는 모두 수치형이였으며, 이를 통해 type을 수치화하여 예측해야 함을 알 수 있었다.


결측치는 존재하지 않았으며, type의 개수는 총 19개였다.


각 type의 개수를 알아본 결과 다음과 같았고, 이를 시각화했을 때 명확하게 클래스에 불균형이 존재한다는 것을 알 수 있었다.
2) 그래프 해석
각 type과 다른 변수들간의 관계를 알아보자.

총 19개의 타입들 중 QSO가 가장 폭넓게 fiberID를 가지고 있으며 나머지 타입들은 600초반정도의 광섬유를 이용한 것으로 파악된다.
* ...이부분 진자 못해먹겠어요 미친 진짜 일주일 내내 이부분만 가지고 고민했는데 머리 하나도 안돌아가요 EDA 너무 어렵다 차라리 모델링만 할래요 진짜 여러분 집단지성 plz
2. 모델링 및 결과
# type을 숫자로 변환
column_number = {}
for i, column in enumerate(submission_df.columns):
column_number[column] = i
def to_number(x, dic):
return dic[x]
train_df['type_num'] = train_df['type'].apply(lambda x: to_number(x, column_number))베이스라인 코드에서 제공해준 코드를 이용해 type을 숫자로 변환해준다.
# train set을 이용해 validation set을 만들어 test set을 이용해 평가 전 검증을 해보고자 함
X = train_df.drop(columns=['type_num', 'type'], axis=1)
y = train_df['type_num']
X_test = test_df주어진 testset에는 type이 없기에 trainset을 최대한 이용하여 학습을 시키고 검증해보려고 한다.
from lightgbm import LGBMClassifier
from sklearn.metrics import log_loss, accuracy_score
from sklearn.model_selection import train_test_split사용한 모델은 트리 기반 LightGBM으로 GBM 모델보다 학습 속도가 빠르다는 장점이 있다.
train_test_split을 이용해 데이터를 분리해주며, 이때 클래스별로 적절한 비율에 따라 데이터를 나누기 위해 stratify라는 값을 이용했다. 이를 통해 클래스 불균형을 조금이나마 막을 수 있을 것이라고 생각했다.
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=100, stratify=y)
model = LGBMClassifier(n_estimators=500,
learning_rate=0.01,
boosting_type='gbdt',
num_leaves=20,
max_depth=15)
model.fit(X_train, y_train)
y_pred_proba = model.predict_proba(X_val)
y_pred_acc = model.predict(X_val)
첫번째로는 다음과 같은 값으로 학습시키고 검증하였다. 정확도는 약 87%이다.
이때 부스팅 타입을 dart로 변경하고, learning_rate을 0.005로 낮추엇다. 또한 max_depth=18로 설정하였고, 과적합을 막기 위해 n_estimators=400으로 낮추었다.
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=100, stratify=y)
model = LGBMClassifier(n_estimators=400,
learning_rate=0.005,
boosting_type='dart', # traditional gradient boosting decision tree
num_leaves=20,
max_depth=18)
model.fit(X_train, y_train)
y_pred_proba = model.predict_proba(X_val)
y_pred_acc = model.predict(X_val)
print(accuracy_score(y_val, y_pred_acc))
정확도가 낮아진 것을 통해 과적합이 생길 가능 성이 매우 높은 상황이며, 이전과 같은 파라미터 값으로 다시한번 학습해본다. boosting_type만 dart로 변경하여 학습시킨 결과 처음보다는 높지 않은 정확도를 보인다.

아무래도 이상치의 영향이 꽤 큰 듯 하다. 이상치를 제거하기에는 불안함이 있으니 정규화 후 학습을 시켜보도록 하겠다.
정규화의 경우 0~1사이의 값으로 정규화를 하는 방법, log를 씌워 정규화하는 방법 등이 있는데, 일단 0~1사이 값으로 변환하는 방법만 사용해보도록 하겠다.
- Standard Scaler
가장 기본적인 정규화 방식으로 정규분포로 변환해주는 스케일러이다.
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 정규화를 해보자.
X = train_df.drop(columns=['type_num', 'type'], axis=1)
y = train_df['type_num']
X_test = test_df
# StandardScaler
std = StandardScaler()
std.fit(X)
# # MinMaxScaler
# mm = MinMaxScaler()
# mm.fit(X)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=100, stratify=y)
model = LGBMClassifier(n_estimators=800,
learning_rate=0.005,
boosting_type='gbdt',
num_leaves=20,
max_depth=15)
model.fit(X_train, y_train)
y_pred_proba = model.predict_proba(X_val)
y_pred_acc = model.predict(X_val)
print(accuracy_score(y_val, y_pred_acc))하이퍼파라미터도 조금 조절해 보니 다음과 같은 결과가 나왔다. 그닥 잘 나오진 않는다.

- MinMaxScaler
최댓값과 최소값을 이용한 스케일러로 자세한 내용은 다음을 참고하자.
sklearn.preprocessing.MinMaxScaler
Examples using sklearn.preprocessing.MinMaxScaler: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24 Image denoising using kernel PCA Image denoising using kernel PC...
scikit-learn.org
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 정규화를 해보자.
X = train_df.drop(columns=['type_num', 'type'], axis=1)
y = train_df['type_num']
X_test = test_df
# # StandardScaler
# std = StandardScaler()
# std.fit(X)
# MinMaxScaler
mm = MinMaxScaler()
mm.fit(X)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.3, random_state=100, stratify=y)
model = LGBMClassifier(n_estimators=1000,
learning_rate=0.005,
boosting_type='gbdt',
num_leaves=20,
max_depth=18)
model.fit(X_train, y_train)
y_pred_proba = model.predict_proba(X_val)
y_pred_acc = model.predict(X_val)
print(accuracy_score(y_val, y_pred_acc))두번째는 MinMaxScaler를 이용했으며, 마찬가지로 하이퍼파라미터를 좀 더 조절해보았더니 결과는 다음과 같이 나왔다.

아무래도 스케일이 문제가 아니라 클래스 불균형의 문제가 가장 큰 듯 하다.
이 부분은 좀 더 공부를 해볼 필요가 있을 것 같다.
3. 인사이트 도출
데이터 클래스 불균형을 해결하기 위해서 오버샘플링 혹은 언더샘플링 방식을 이용해야 할 것으로 판단된다.
이때 특정 클래스만 언더샘플링 후 과하게 적은 클래스는 삭제해 학습 결과를 바탕으로 학습한 클래스가 아니라면 삭제된 그 클래스로 예측할 수 있도록 하면 어떨까 싶다. 다만 어떻게 구현해야 할지는 아직 더 알아봐야할 것 같다.
4. 아쉬운점
EDA 너무 어렵다. 왜 내가 원하는 형태로는 그래프가 나오지 않는걸까?
log_loss 함수를 이용하려는데 튜플형을 받지 않아 이 값을 구하지 못했는데, 이 부분을 해결할 방안을 찾아봐야할 것 같다.
하이퍼파라미터 최적화 하려고 했는데 2시간을 돌렸는데도 학습이 안끝나 그냥 손으로 하나하나 수정하는 것이 빠를 듯 하다.
클래스 불균형...
아웃라이어보다 사실 클래스 불균형의 영향이 제일 큰 듯 하다. 이 기회로 오버샘플링, 언더 샘플링에 대해 공부를 해보고 적용해봐야겠다.
어렵다.
혼자하려니 머리 터질 것 같다.
앞으로의 계획을...... 좀 수정해봐야겠다. 회귀를 나가는 것이 맞는가?
그래도 전반적으로 훑는게 좋지 않은가? vs 분류 하나라도 제대로 해보자
여러분들의 선택은?
제 과정에 대한 피드백과 약 두달 반정도의 학습을 통한 여러분들의 의견도 주십쇼.
감사합니다.
다만. 과제가 많다는 것은 재고하지 않을 예정입니다..
'💡 WIDA > DACON 분류-회귀' 카테고리의 다른 글
| [DACON/조아영] 천체 분류 경진대회 도메인 더 뜯어보기: Type (1) | 2023.05.26 |
|---|---|
| [DACON/김민혜] 천체 분류 경진대회 (5) | 2023.05.06 |
| [DACON/최다예] 프로젝트 에세이 (5) | 2023.05.05 |
| [DACON/김경은] 프로젝트 에세이 (4) | 2023.05.05 |
| [DACON/김세연] 프로젝트 에세이 (4) | 2023.05.05 |