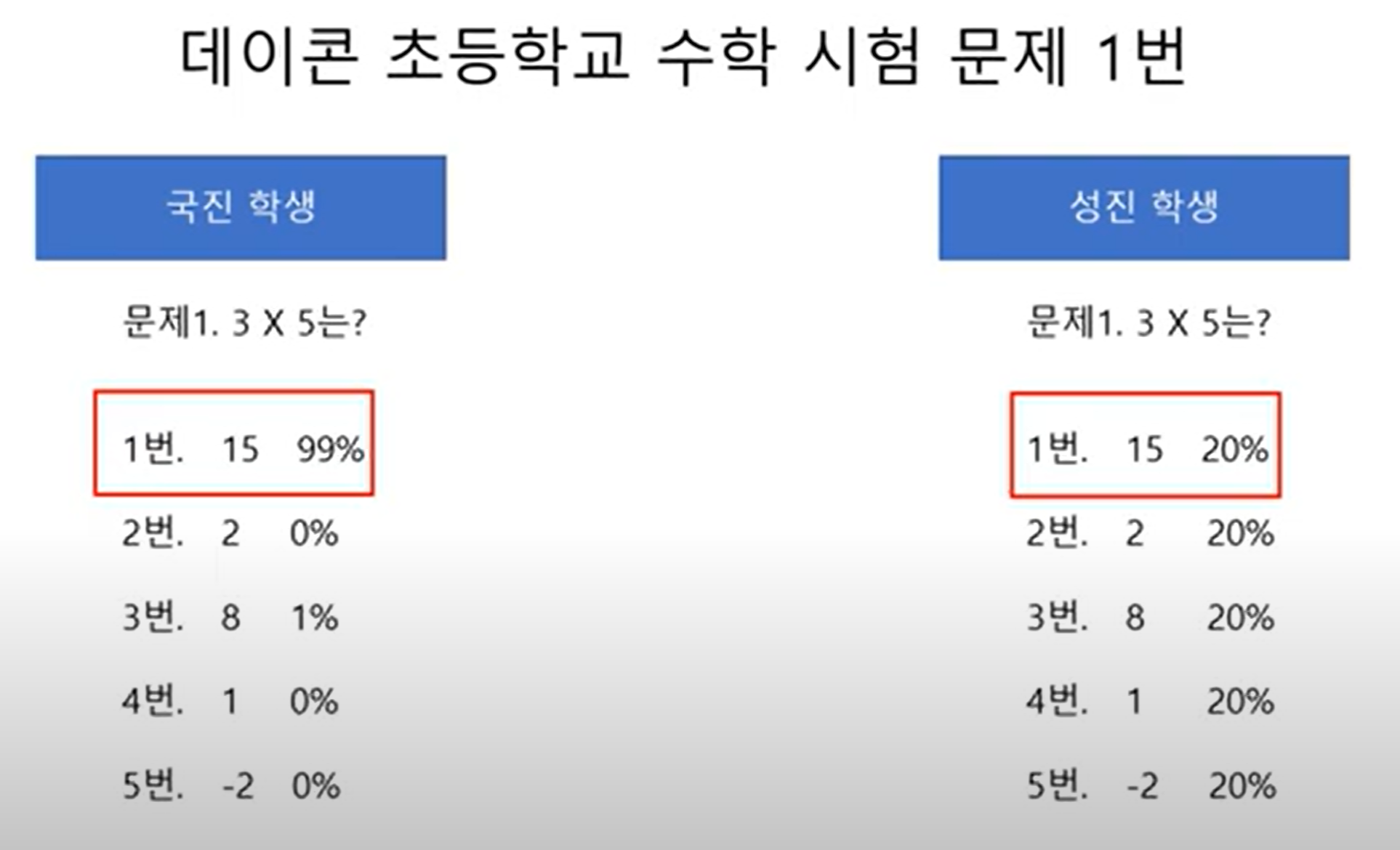
[2팀/윤서현] 4차시 파이썬 과제 - 반복문
#1 for문을 사용해 1부터 100까지의 숫자를 출력해 보세요 for i in range(1,101,1): print(i) #2 A학급에 총 10명의 학생이 있다. 이 학생들의 중간고사 점수는 다음과 같다. for문을 사용해 서 A학급의 평균 점수를 구해보세요. A = [70,60,55,75,95,90,80,80,85,100] total = 0 for score in A: total += score average = total/10 print(average) A = [70,60,55,75,95,90,80,80,85,100] total = 0 for score in A: total += score average = total / len(A) print(average) #3 다음 for문과 동일한 기능을 ..