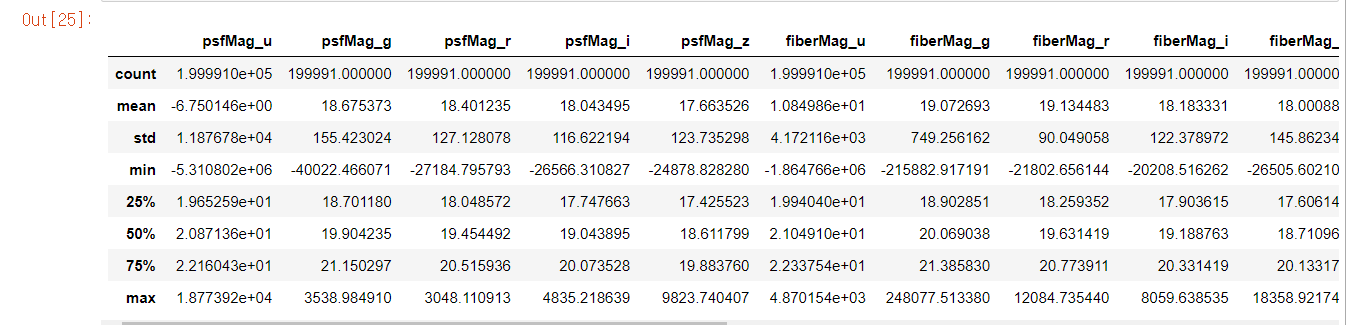
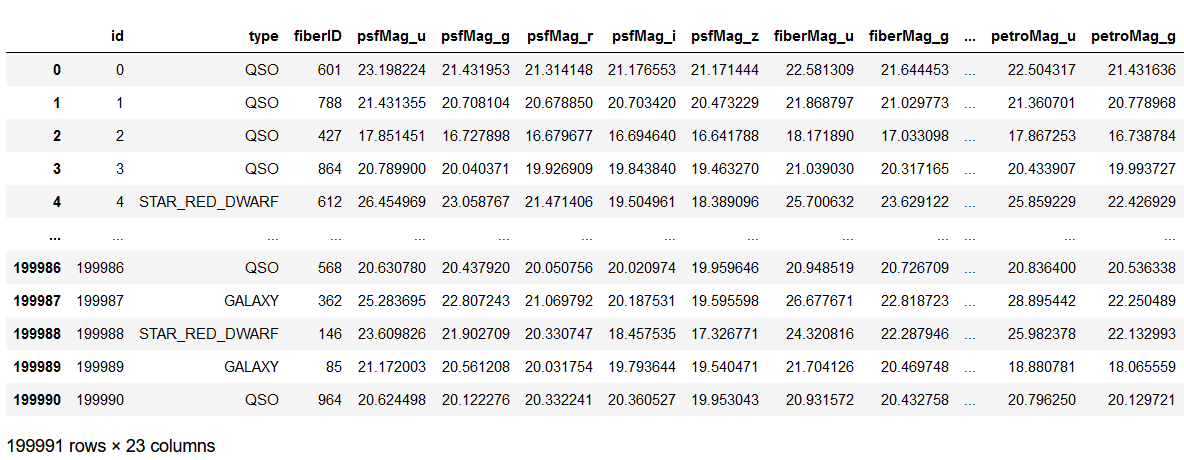
jupyter notebook 환경에서 작업해봤습니다~ 필요한 라이브러리 불러오기 #필요한 라이브러리 불러오기 import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns color = sns.color_palette() sns.set_style('darkgrid') # 그래프 해상도 업그레이드 %config InlineBackend.figure_format = 'retina' # 경고문 무시 import warnings warnings.filterwarnings('ignore') %matplotlib inline의 의미 notebook을 실행한 브라우저에서 바로 그..